Introduction
We have seen so far how to work with data: importing, cleaning, and visualizing it. Performing analysis of what has happened allows us to take a determined action to change the course of a business. However, the true power of data science lies in using this data to predict the future.
Predictive analysis is a technique that every Data Scientist must master, and Machine learning provides us with robust algorithms to make these predictions.
Machine learning is the study of computer algorithms that improve automatically through experience. It is a subset of artificial intelligence where algorithms create mathematical models based on sample data, known as “training data”, to make predictions or decisions without being explicitly programmed to do so. Applications range from recommendation engines (like Netflix or Spotify) to fraud detection and self-driving cars (Michell 1997).
A good data scientist knows how to build prediction algorithms using machine learning. In this book, we will focus on the two main approaches:
We will explore two primary approaches to machine learning. Supervised Learning involves training models on labeled data where we know the correct answer, allowing us to predict outcomes for new, unseen data—either as numbers (regression) or categories (classification). In contrast, Unsupervised Learning deals with unlabeled data, where the goal is to discover hidden patterns, structures, or groupings (clustering) without a pre-defined answer key.
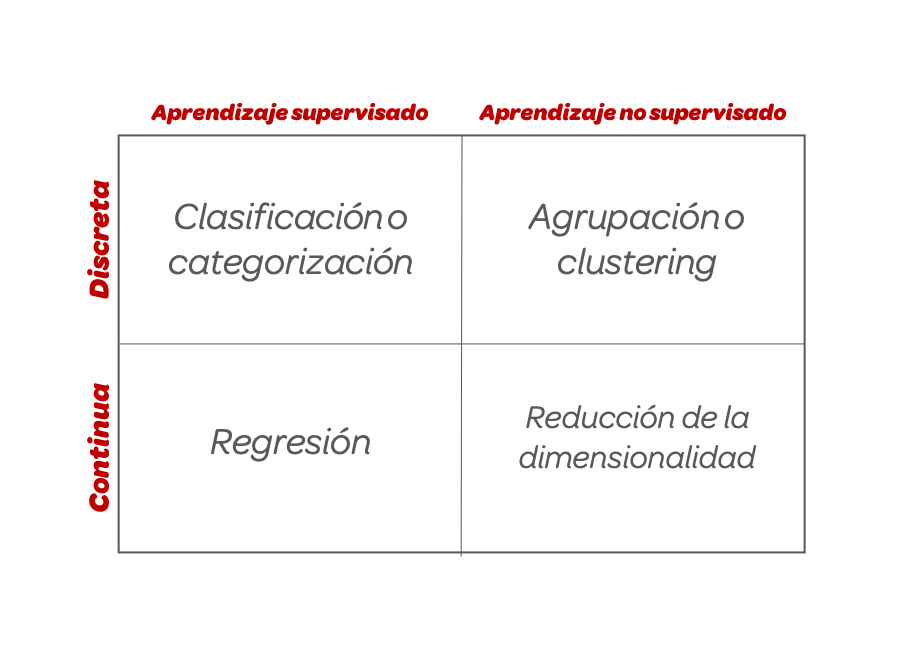
Keep in mind that there are also other approaches, such as semi-supervised learning or reinforcement learning where the algorithm learns from a real or synthetic environment. These approaches will not be covered in this book, which focuses on the foundational techniques for starting out as a data scientist.
10.7 Learning Objectives
By the end of this chapter, you will be able to:
In this chapter, we will learn to distinguish between supervised and unsupervised learning approaches. We will implement core algorithms such as k-Nearest Neighbors (kNN), Logistic Regression, and Random Forest for classification tasks, and build regression models to predict continuous variables. Additionally, we will evaluate model performance using essential metrics like confusion matrices and ROC curves, apply clustering techniques to segment data, and select the optimal model using the modern tidymodels framework.
10.8 Chapter Structure
We will cover the two main approaches to machine learning:
Our journey covers these two fundamental pillars. We begin with Supervised Learning, focusing on models that learn from historical data to predict future outcomes, covering both classification and regression problems. We then move to Unsupervised Learning, techniques designed to find structure in unlabeled data, such as grouping similar customers or reducing complex datasets to their essential features.
Keep in mind that there are also other approaches, such as semi-supervised learning or reinforcement learning where the algorithm learns from a real or synthetic environment. These approaches will not be covered in this book, which focuses on the most commonly used approaches for starting out as a data scientist.